
In recent years, anime has become increasingly popular worldwide, and the number of anime available online has grown exponentially. With so many options to choose from, it can be challenging to select the perfect one to suit their unique tastes. To address this issue, machine learning techniques has been used to develop personalized anime recommendation systems. By analyzing an individual’s viewing history and preferences, these systems can suggest anime titles that are more likely to appeal to them, based on factors such as genre, themes, and style. In this way, anime fans can discover new shows that are tailored to their specific interests, and spend less time searching. This article explores the use of machine learning in anime recommendation systems and discusses how they can enhance the anime viewing experience.
The process began by gathering data from MyAnimeList, a website dedicated to anime similar to IMDb. Over 5000 anime titles and user profiles were collected using Scrapy, Beautiful-soup and stored as JSON objects in MongoDB. The collected information includes names, descriptions, directors, vocal casts, theme songs, reviews, and more. Below is an example demonstrating the format of the collected data.
Examples of data stored in MangoDB.
{'_id': 'Yaiba',
'themesongs': [['"Yuuki ga Areba (勇気があれば)" by Kabuki Rocks (カブキロックス)',
'"Shinchigakunaki Tatakai! (神智学無き戦い!)" by Kabuki Rocks (カブキロックス)']],
'description': ["Kurogane Yaiba is a boy who doesn't want to become what any regular kid would: A samurai. That's why he undergoes a hard training with his father, knowing only the forest as his world. Then, one day, he is sent to Japan, where he has to deal with a whole new civilized reality, meeting the Mine family, the evil Onimaru and even the legendary Musashi, having lots of dangerous adventures, becoming stronger everyday.(Source: ANN, edited) "],
'reviews': ['which are really stupid but it all succeds in tickling us!!the storycharacter and enjoyment is quite okwell i personally disliked the op and ed and art also seems quite ok {not many cute girls :( }its a lot of fun overall the series i ll definately say give 1 shot only to the 1st epi!!!ull automatically get hooked to the series atleast i did !well i hope u liked my review plz ratemy 1st reviewread more'],
'img_url': 'https://myanimelist.cdn-dena.com/images/anime/5/71953.jpg'}
The table illustrates an example of a user’s watched history, and the accompanying table displays ratings for 5 different anime given by 5 distinct users. The ratings are on a scale of 1 to 10, with 10 representing the highest level of favorability.
| Anime/score | User1 | User2 | User3 | User4 | User5 |
|---|---|---|---|---|---|
| Fairy Tail | 10 | 8 | 10 | 5 | |
| Kimi no na wa | 10 | 9 | 4 | ||
| No game no life | 9 | 9 | |||
| Tokyo Ghoul | 7 | 9 | |||
| One Piece | 10 | 9 |
How does this recommender system works ?
Broadly speaking, there are two common algorithms used in the recommendation systems, collaborative filtering and content-based filtering. Collaborative filtering works by analyzing the viewing histories and ratings of multiple users. The system identifies users who have similar viewing and rating patterns and groups them into clusters. It then makes recommendations based on the preferences of users in the same cluster. For example, if many Marvel fans has enjoyed Tom and Jerry in their past, the system will likely recommend Tom and Jerry to those Marvel fans who has not watched it yet. In other words, it makes predictions based on the response of other users who share similar tastes. Content-based filtering, on the other hand, makes recommendations based on the content of the anime themselves. This approach involves analyzing the attributes, such as genre, theme, plot, character and story background,. The system then recommends anime to users based on their preferences for these attributes. For example, if a user enjoys watching romantic comedies with high school settings, the system will search for anime with similar attributes.
Both methods have their pros and cons. A major appeal of collaborative filtering is its flexibility in dealing with various data aspects. Collaborative filtering requires an active user data base with effective rating system and it does not work well with new user profiles or new anime with no ratings or reviews, known as cold start problem. It also relies heavily on the availability of user data, which can lead to sparsity and bias in data. A content based filtering is more friendly to new anime but is more exclusive to users’ own experience, and does not consider social factors such as popularity.
A more effective solution would be a hybrid system that combines both methods. While there are many blogs online discussing these two methods, few dive into how they work in practice. To begin with, it is important to understand the concept of the cold start problem and how it arises. We can conceptualize the rating system as a matrix, denoted as Rrating, where the matrix contains the scores of all anime titles rated by all users. In our particular case, the matrix size will be 5000 shows by 5000 users, and each row will represent the ratings given by a user, with a value of 0 indicating that the user has not watched the anime.
[[ 10 0 0 0 8 9 0 9 0 0 10 0 5 0 10 ...]
[ 0 0 0 9 0 0 0 8 0 0 4 0 0 0 8 ...]
[ 9 0 0 0 0 8 9 0 0 0 0 0 0 0 0 ...]
[ 0 3 1 0 0 0 0 0 7 3 9 0 0 0 0 ...]
[ 0 0 0 0 0 0 0 0 0 0 0 0 9 0 0 ...]]
Let’s take a look at Row 5, which represents a new user. Typically, most users will have only watched a small fraction of the thousands of anime titles available on the platform. Assuming an average user spends about one hour per week on anime and each show has around 12 episodes of 20 minutes each, that would amount to roughly 152 hours per year, or about 20 shows per year. Consequently, the rating matrix will be extremely sparse, with most elements being zero. As the platform expands and more users join, the sparsity problem will continue to grow more severe.
Figure 1. Hybrid recommender work flow. A layout structure of my code.

A: Collaborative Filtering Workflow
The following image displays a user-item interaction matrix obtained from the ratings of six shows given by six users. Traditional collaborative filtering include measuring user similarity by calculating Pearson correlation or cosine similarity between normalized user vectors. Then combine the weighted average scores given by neighbors to estimate user’s score on the unseen show. A modern solution called matrix factorization, initially introduced by Simon Funk in 2006 in the Netflix Prize competition, has a better approach in handling this user-item matrix. Instead of directly computing similarity between users, matrix factorization transforms the original matrix into two lower-dimensional matrices - one representing users and the other representing items using technique called singular value decomposition (SVD). These lower-dimensional matrices capture the latent factors or features that determine the user’s preference for a particular item, and can be used to predict missing ratings. Matrix factorization can provide more accurate predictions and is more scalable than traditional collaborative filtering methods.
Figure 2. User-item matrix decomposition 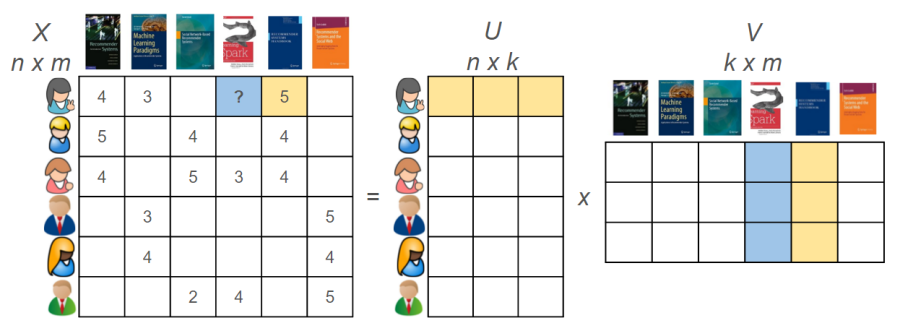 \(R=\begin{bmatrix}
5 & 3 & 0 & 1 \\
4 & 0 & 0& 1\\
1 & 1 & 0& 5\\
0 & 1 & 5& 4\\
\end{bmatrix}
\rightarrow\;\;\;\; U \times V\;\;
\rightarrow \;\;\hat{R}=\begin{bmatrix}
4.9& 2.5 &2.2 &0.9 \\
4.2 & 0.5 & 3.4& 1\\
1.5 & 0.3 & 4.5& 3.9\\
1.1 & 0.9 & 4.9& 3.2\\
\end{bmatrix}\)
Rating matrix R can be expressed as the product of two lower-dimensional matrices: U (user matrix) and V (item matrix). Assume k=3 latent factors, which means we assume that there are three underlying factors that determine how users rate the items (e.g. action vs romance vs adventure, animation quality vs length vs vocal, etc). We initialize U and V randomly, then use gradient descent to optimize the matrices based on the mean squared error loss between the predicted ratings and actual ratings in R. We can then use these matrices to predict the missing values in R, by taking the dot product of the corresponding user and item vectors.
\(R=\begin{bmatrix}
5 & 3 & 0 & 1 \\
4 & 0 & 0& 1\\
1 & 1 & 0& 5\\
0 & 1 & 5& 4\\
\end{bmatrix}
\rightarrow\;\;\;\; U \times V\;\;
\rightarrow \;\;\hat{R}=\begin{bmatrix}
4.9& 2.5 &2.2 &0.9 \\
4.2 & 0.5 & 3.4& 1\\
1.5 & 0.3 & 4.5& 3.9\\
1.1 & 0.9 & 4.9& 3.2\\
\end{bmatrix}\)
Rating matrix R can be expressed as the product of two lower-dimensional matrices: U (user matrix) and V (item matrix). Assume k=3 latent factors, which means we assume that there are three underlying factors that determine how users rate the items (e.g. action vs romance vs adventure, animation quality vs length vs vocal, etc). We initialize U and V randomly, then use gradient descent to optimize the matrices based on the mean squared error loss between the predicted ratings and actual ratings in R. We can then use these matrices to predict the missing values in R, by taking the dot product of the corresponding user and item vectors.
B: Content-based Filtering workflow
A way to understand content-based filtering is to see it as a classification problem, where the system identifies relevant features in the content that are highly correlated with the user’s preferences. Recommendations are then made by comparing the user’s profile to the content of each item in the collection. The inputs are descriptions of anime stories and the goal is to identify the key topics or themes present in the text by extracting and grouping related keywords. TF-IDF is a common method used for text extraction that calculates the importance of a specific word in a given document. Words that appear frequently across all documents, such as “people” or “place,” are given a lower importance than words that appear infrequently but suggest a specific theme or topic, such as “wolf,” “magic,” or “spirit”. In this project, 30 different anime topics were identified by extracting the key phrases from all the story descriptions. For instance, Topic 7 is centered on solving crimes, with Detective Conan being the most representative example.
Examples:
Topic #1: Special, release, air, recap, feature
Topic #2: Earth, Planet, space, alien, ship
Topic #3: High, school, junior, student, classmate
Topic #4: Team, soccer, player, match, baseball
Topic #5: Human, race, mankind, god, survive, extinct
Topic #6: Magic, witch, magician, kingdom, wish
Topic #7: Mystery, solve, appear, past, shadow, kill
Topic #8: Demon, king, hero, lord, seal, defeat, mission
Topic #9: Love, feel, fall, relationship, confess, heart
Then we can calculate an associated probability for each topic for a given anime. For example
| Anime/Topics | Topic 2 | Topic 3 | Topic 7 | Topic 8 | Topic 9 |
|---|---|---|---|---|---|
| Fairy Tail | 0.01 | 0.12 | 0.00 | 0.67 | 0.00 |
| Kimi no na wa | 0.11 | 0.87 | 0.02 | 0.01 | 0.54 |
| No game no life | 0.35 | 0.23 | 0.34 | 0.01 | 0.35 |
| Tokyo Ghoul | 0.02 | 0.56 | 0.76 | 0.12 | 0.00 |
| One Piece | 0.05 | 0.00 | 0.00 | 0.45 | 0.00 |
We can determine a user’s preference for different topics by taking an average of all the anime topics they have watched in the past. To generate recommendations, we then calculate the cosine similarity between the user’s topic matrix and the anime topic matrix. Finally, we combine the results obtained from the two recommenders.
Future Improvements
Incorporating contextual information, such as location, country, ethnicity, age to enhance the accuracy of recommendations by tailoring them to the user’s current situation. Use deep learning techniques, such as neural networks, to create more sophisticated models that can capture more complex patterns and relationships between users and items.
Conclusion
Both methods have their strengths and limitations, and they can be combined to create a hybrid recommender system. The effectiveness of these methods can be further improved with advancements in natural language processing and machine learning techniques. Overall, recommender systems play a critical role in providing personalized experiences to users and are increasingly important in today’s digital landscape.
Reference